
Getting a list of Blink Components
This post provides a quick way to retrieve and filter the list of Blink components from a JSON file hosted by Chromium. The provided JavaScript snippets demonstrate how to fetch and process the component list, filtering for entries that begin with "Bli". The next step is figuring out how to programmatically get a list of OWNERS. Read More
I lead the Chrome Developer Relations team at Google.
We want people to have the best experience possible on the web without having to install a native app or produce content in a walled garden.
Our team tries to make it easier for developers to build on the web by supporting every Chrome release, creating great content to support developers on web.dev, contributing to MDN, helping to improve browser compatibility, and some of the best developer tools like Lighthouse, Workbox, Squoosh to name just a few.
I love to learn about what you are building, and how I can help with Chrome or Web development in general, so if you want to chat with me directly, please feel free to book a consultation.
I'm trialing a newsletter, you can subscribe below (thank you!)




River Dee in Llangollen before and after heavy rain
I love driving through North Wales, especially Llangollen, a town nestled by the River Dee. In summer, the river's flow is gentle enough to paddle in (with caution!). But after a recent heavy rain (post-Storm Dennis), the river transformed! The power and height of the water were incredible, almost reaching the footpath wall. Check out Llangollen - it's worth a visit, rain or shine! Read More
Scroll to text bookmarklet
Just saw that Scroll To Text Fragment is launching in Chrome 81! This feature lets you link to specific text within a page, which is awesome. I created a bookmarklet that grabs your selected text and generates a link using the new :~:text= fragment identifier. Drag the "Find in page" link to your bookmarks bar to try it out. The bookmarklet currently selects whole words, but I'm planning on adding some logic to handle partial word selections better. You can also easily modify the bookmarklet to copy the generated link to the clipboard instead of opening a new window.
Read More
What do you want from a Web Browser Developer Relations team?
Celebrating my 10th anniversary at Google working on Chrome and leading a Developer Relations team. As we plan for the next few years, I'm reflecting on how we can improve Developer Satisfaction. Inspired by recent feedback on Apple's developer relations, I'm curious to hear your thoughts on what a web browser developer relations team should prioritize. What can we do more of? Less of? How can we best support you and your team? Share your opinions, especially broad strategic ideas. Read More
Thinking about Developer Satisfaction and Web Developers
This post discusses the importance of developer satisfaction, particularly for web developers, and how the MDN Web Developer Needs Assessment has influenced Chrome's web platform priorities for 2020. My hypothesis is that improving the web platform will lead to increased developer satisfaction, more content creation, and happier end-users. Based on the MDN survey data, key areas for improvement include browser compatibility, testing, documentation, debugging, framework integration, and privacy & security. Chrome is committed to working with the web ecosystem to address these challenges and increase developer productivity and satisfaction. We'll share more specific plans in the coming weeks and welcome your feedback on these focus areas and how Chrome can better engage with the developer community. Read More
Hiring: Chrome Privacy Sandbox Developer Advocate — 🔗
It's looking like 2020 will be a big year for Privacy across the web and our team (Chrome) is no exception.
Chrome has a rather large number of projects that are coming in the following years that will continue to improve the privacy of all users on the web and we need the help of an awesome Developer Advocate to ensure that the entire cross-browser privacy story is heard, understood and implemented across the web.
The Developer Advocate role will help to accelerate the adoption of security and privacy related primitives from all browsers (think about all the great work browsers like Firefox, Safari, Brave etc are doing) across the web ecosystem and to make sure that our engineering and product teams are prioritising the needs of users and developers. It's not going to be easy, because a lot of these changes impact the way developers build sites today; for example, the Same-Site change that is landing in Chrome imminently requires developers of widgets and anything that is hosted on a 3rd party origin meant to be used in a 1st party context, to declare that the correct SameSite attribute, lest they be automatically set to SameSite=Lax, which will restrict their usage slightly.
There's going to be a lot of work to do, so being able to work with companies, frameworks and libraries in the ecosystem is going to be a key part of this role.
If you're interested, my email is paulkinlan@google.com - or you can apply on the Job posting directly.
Correct image orientation for images - Chrome 81
Chrome 81 finally fixes a long-standing bug where images taken in portrait mode on phones were displayed in landscape. Now, images will respect the orientation from the EXIF data by default, unless overridden with the CSS attribute image-orientation: none. Check out the demo!
Read More
Light fork of SimpleImage for Editor.js — 🔗
I love Editor.js. It's a nice simple block editor that I use to write these posts. It has a host of good plugins that enable you to extend the capabilities of the editor, such as the SimpleImage tool that allows you to add images to the editor without having to upload them.
It's the SimpleImage that I briefly want to talk about. It's a good tool, but it has two problems, 1) I can only drag images on to the editor, I can't "add" an image; 2) It uses base64 data URL's to host the image, this is a waste of memory and it should be using blob URLs.
I wrote a simple fork that addresses these two pain points. The first is that it uses less memory because it uses blob URLs. The second is that now you can add images in when adding in a new Block to the editor.
In fact, the following images are added using this new way.
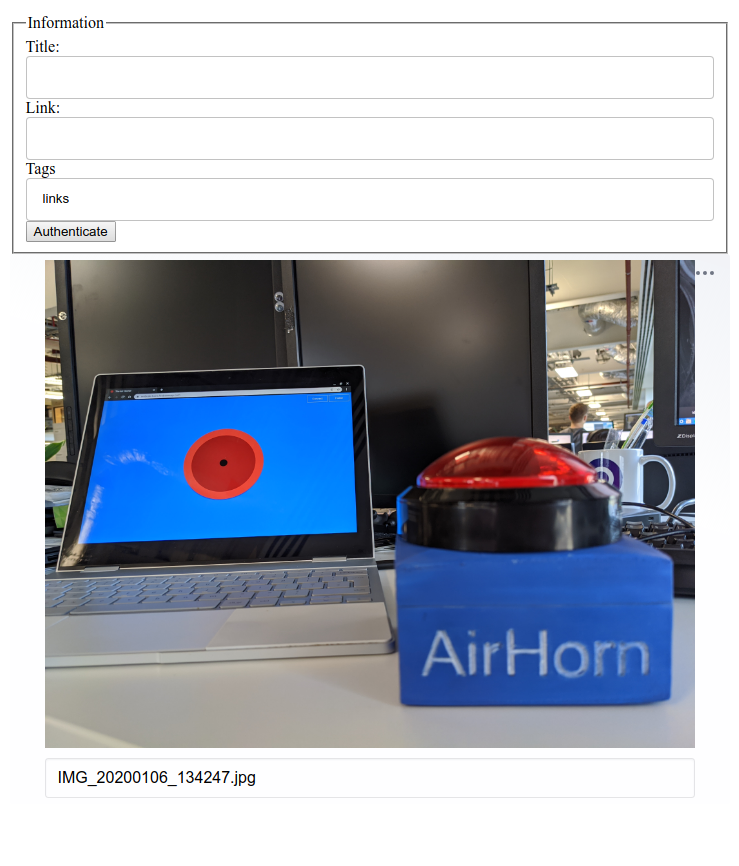
Airhorner with added Web USB — 🔗
This new year Andre Bandarra left me a little surprise on my desk: A physical airhorner built with Web USB!
Check it out, well actually it will be hard, Andre created a small sketch for an Arduino Uno that connects over USB that is not yet available, however the code on the site is rather neat and not too complex if you are experienced with any form of USB programming.
Andre's code connects to the device and waits for the user to approve, configures the connection, and then continuously reads from the device looking for the string 'ON' (which is a flag that is set when the button is pressed).
const HardwareButton = function(airhorn) {
this.airhorn = airhorn;
this.decoder = new TextDecoder();
this.connected = false;
const self = this;
this._loopRead = async function() {
if (!this.device) {
console.log('no device');
return;
}
try {
const result = await this.device.transferIn(2, 64);
const command = this.decoder.decode(result.data);
if (command.trim() === 'ON') {
airhorn.start({loop: true});
} else {
airhorn.stop();
}
self._loopRead();
} catch (e) {
console.log('Error reading data', e);
}
};
this.connect = async function() {
try {
const device = await navigator.usb.requestDevice({
filters: [{'vendorId': 0x2341, 'productId': 0x8057}]
});
this.device = device;
await device.open();
await device.selectConfiguration(1);
await device.claimInterface(0);
await device.selectAlternateInterface(0, 0);
await device.controlTransferOut({
'requestType': 'class',
'recipient': 'interface',
'request': 0x22,
'value': 0x01,
'index': 0x00,
});
self._loopRead();
} catch (e) {
console.log('Failed to Connect: ', e);
}
};
this.disconnect = async function() {
if (!this.device) {
return;
}
await this.device.controlTransferOut({
'requestType': 'class',
'recipient': 'interface',
'request': 0x22,
'value': 0x00,
'index': 0x00,
});
await this.device.close();
this.device = null;
};
this.init = function() {
const buttonDiv = document.querySelector('#connect');
const button = buttonDiv.querySelector('button');
button.addEventListener('click', this.connect.bind(this));
button.addEventListener('touchend', this.connect.bind(this));
if (navigator.usb) {
buttonDiv.classList.add('available');
}
};
this.init();
};
If you are interested in what the Arduino side of things looks like, Andre will release the code soon, but it's directly inspired by the WebUSB examples for Arduino.
Matsushima, Miyagi
Matsushima, Miyagi is a beautiful seaside town an hour from Sendai. Famous for its fresh oysters, islands, and red bridges, it's a charming place to visit. While the 2011 tsunami impacted the area, the town has recovered remarkably well. I found the quiet, cold atmosphere when I went added to its appeal. Read More
Yamadera, Yamagata
I took a day trip to the 1000-year-old Yamadera Temple in Yamagata, Japan. The climb to the top wasn't too difficult and offered breathtaking views of the valley. It was a quiet day with few other visitors, unlike busier weekends and holidays. The oldest building there is around 400 years old. Read More
Modern Mobile Bookmarklets with the ShareTarget API
Mobile devices lack the bookmarklet functionality found in desktop browsers. However, the ShareTarget API offers a potential workaround. This API allows web apps to be installed and receive native share actions, similar to how the Twitter PWA handles shared links and files. By leveraging this API, developers can create mini-apps that perform actions on shared data. This approach involves defining how to receive data in a manifest file and handling the request in a service worker. I've created examples for Hacker News, Reddit, and LinkedIn demonstrating how to utilize the ShareTarget API. While not a perfect replacement for desktop bookmarklets, this offers a new level of hackability for mobile web experiences. Read More
Pixel 4XL Infrared sensor via getUserMedia
The Pixel 4 XL's infrared camera, used for face detection, can be accessed through the standard getUserMedia API. A live demo showcasing this can be found at the provided link. Using the IR camera via getUserMedia blocks the phone's face unlock feature. This post invites readers to brainstorm potential applications of user-accessible infrared camera capabilities. An update mentions Francois Beafort's contribution to Blink, adding 'infrared' to the camera name if the device supports it, making camera identification more convenient. Read More
Sunset over Tokyo from Shibuya
Snapped a quick pic of a stunning Tokyo sunset from my Shibuya office window. Read More
Harlech Castle
Had a wonderful time exploring the magnificent Harlech Castle in North Wales with my kids. The castle is well-preserved and steeped in history, perched atop a hill with breathtaking views of Snowdonia and the Irish Sea. Unlike my previous visit to Carlisle Castle, this trip was purely focused on enjoying the stunning scenery. Read More
Puppeteer Go — 🔗
I love Puppeteer - it lets me play around with the ideas of The Headless Web - that is running the web in a browser without a visible browser and even build tools like DOM-curl (Curl that runs JavaScript). Specifically I love scripting the browser to scrape, manipulate and interact with pages.
One demo I wanted to make was inspired by Ire's Capturing 422 live images post where she ran a puppeteer script that would navigate to many pages and take a screenshot. Instead of going to many pages, I wanted to take many screenshots of elements on the page.
The problem that I have with Puppeteer is the opening stanza that you need to do anything. Launch, Open tab, navigate - it's not complex, it's just more boilerplate than I want to create for simple scripts. That's why I created Puppeteer Go. It's just a small script that helps me build CLI utilities easily that opens the browser, navigates to a page, performs your action and then cleans up after itself.
Check it out.
const { go } = require('puppeteer-go');
go('https://paul.kinlan.me', async (page) => {
const elements = await page.$$("h1");
let count = 0;
for(let element of elements) {
try {
await element.screenshot({ path: `${count++}.png`});
} catch (err) {
console.log(count, err);
}
}
});
The above code will find the h1 element in my blog and take a screenshot. This is nowhere near as good as Ire's work, but I thought it was neat to see if we can quickly pull screenshots from canisuse.com directly from the page.
const { go } = require('puppeteer-go');
go('https://caniuse.com/#search=css', async (page) => {
const elements = await page.$$("article.feature-block.feature-block--feature");
let count = 0;
for(let element of elements) {
try {
await element.screenshot({ path: `${count++}.png`});
} catch (err) {
console.log(count, err);
}
}
});
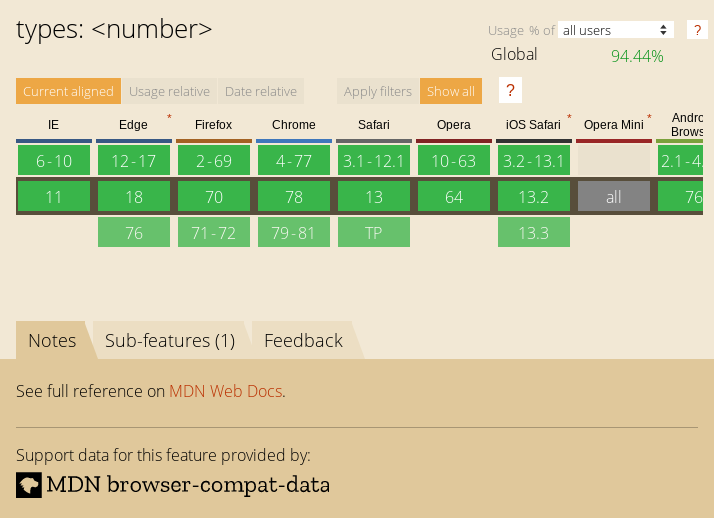
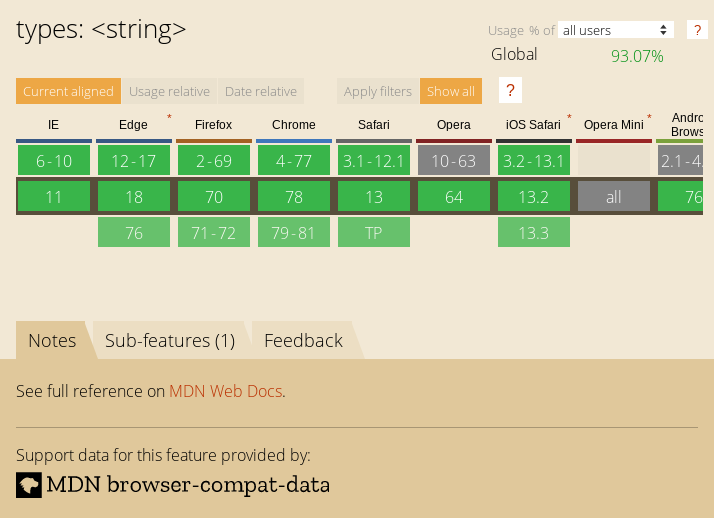
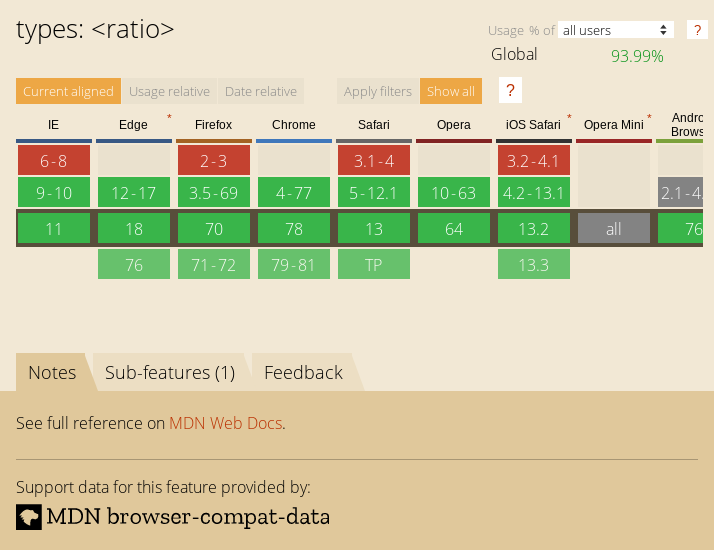
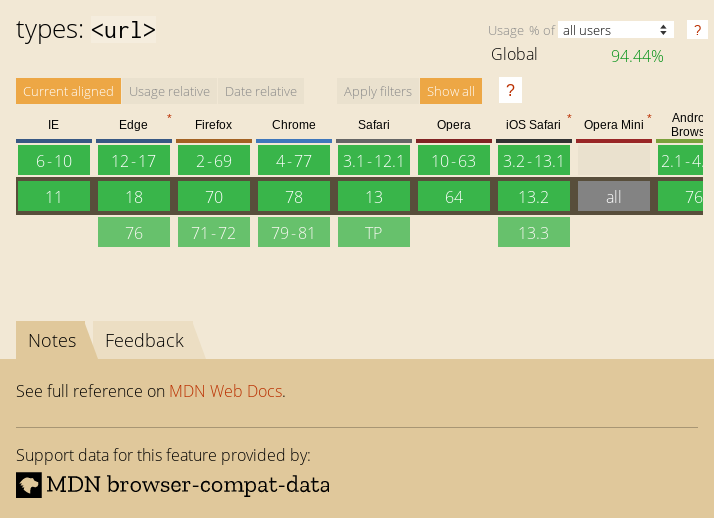
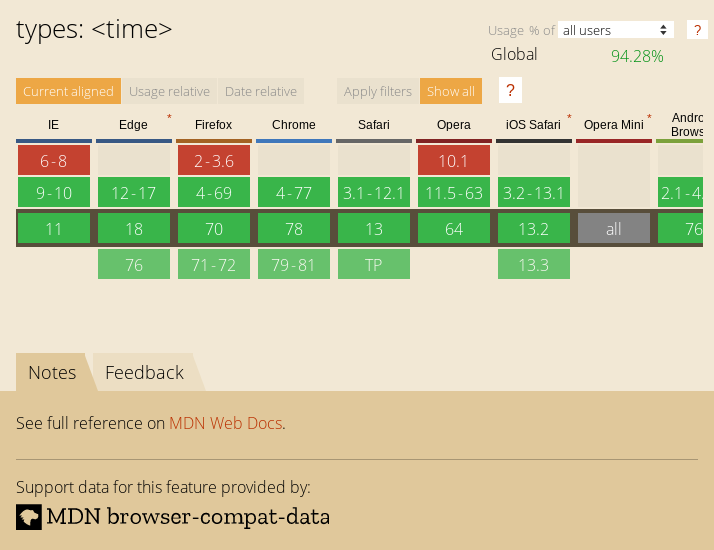
Enjoy!
A simple video insertion tool for EditorJS — 🔗
I really like EditorJS. It's let me create a very simple web-hosted interface for my static Hugo blog.
EditorJS has most of what I need in a simple block-based editor. It has a plugin for headers, code, and even a simple way to add images to the editor without requiring hosting infrastructure. It doesn't have a simple way to add video's to the editor, until now.
I took the simple-image plugin repository and changed it up (just a tad) to create a simple-video plugin (npm module). Now I can include videos easily in this blog.
If you are familar with EditorJS, it's rather simple to include in your projects. Just install it as follows
npm i simple-video-editorjs
And then just include it in your project as you see fit.
const SimpleVideo = require('simple-video-editorjs');
var editor = EditorJS({
...
tools: {
...
video: SimpleVideo,
}
...
});
The editor has some simple options that let you configure how the video should be hosted in the page:
- Autoplay - will the video play automatically when the page loads
- muted - will the video not have sound on by default (needed for autoplay)
- controls - will the video have the default HTML controls.
Below is a quick example of a video that is embedded (and showing some of the options).
Anyway, I had fun creating this little plugin - it was not too hard to create and about the only thing that I did was defer the conversion to base64 which simple-images uses and instead just use the Blob URLs.
Test post Video upload
This is a test post to ensure video uploads are working correctly. If you can see the video below, the test was successful. Read More
Friendly Project Name Generator with Zeit — 🔗
I've got some ideas for projects that make it easier to create sites on the web - one of the ideas is to make a netlify-like drag and drop interface for zeit based projects (I like zeit but it requires a tiny bit of cli magic to deploy).
This post covers just one small piece of the puzzle: creating project names.
Glitch is a good example of this, when you create a project it gives it a whimsical randomly generated name. The team also created a good dictionary of fairly safe words that combine well (and if you want they have a simple server to host).
So, the side project this Sunday was to create a simple micro-service to generate random project names using Zeit's serverless-functions and the dictionary from Glitch.
And here it is (code), it's pretty short and not too complex.
const words = require("friendly-words");
function generate(count = 1, separator = "-") {
const { predicates, objects } = words;
const pCount = predicates.length;
const oCount = objects.length;
const output = [];
for (let i = 0; i < count; i++) {
const pair = [predicates[Math.floor(Math.random() * pCount)], objects[Math.floor(Math.random() * oCount)]];
output.push(pair.join(separator));
}
return output;
}
module.exports = { generate }
If you don't want to include it in your project directly, you can use the HTTP endpoint to generate random project names (in the form of "X-Y") by making a web request to https://friendly-project-name.kinlan.now.sh/api/names, which will return something like the following.
["momentous-professor"]
You can also control how many names to generate with the a query-string parameter of count=x, e.g. https://friendly-project-name.kinlan.now.sh/api/names?count=100
["melon-tangerine","broad-jury","rebel-hardcover","far-friend","notch-hornet","principled-wildcat","level-pilot","steadfast-bovid","holistic-plant","expensive-ulna","sixth-gear","political-wrench","marred-spatula","aware-weaver","awake-pair","nosy-hub","absorbing-petunia","rhetorical-birth","paint-sprint","stripe-reward","fine-guardian","coconut-jumbo","spangle-eye","sudden-euphonium","familiar-fossa","third-seaplane","workable-cough","hot-light","diligent-ceratonykus","literate-cobalt","tranquil-sandalwood","alabaster-pest","sage-detail","mousy-diascia","burly-food","fern-pie","confusion-capybara","harsh-asterisk","simple-triangle","brindle-collard","destiny-poppy","power-globeflower","ruby-crush","absorbed-trollius","meadow-blackberry","fierce-zipper","coal-mailbox","sponge-language","snow-lawyer","adjoining-bramble","deserted-flower","able-tortoise","equatorial-bugle","neat-evergreen","pointy-quart","occipital-tax","balsam-fork","dear-fairy","polished-produce","darkened-gondola","sugar-pantry","broad-slouch","safe-cormorant","foregoing-ostrich","quasar-mailman","glittery-marble","abalone-titanosaurus","descriptive-arch","nickel-ostrich","historical-candy","mire-mistake","painted-eater","pineapple-sassafras","pastoral-thief","holy-waterlily","mewing-humor","bubbly-cave","pepper-situation","nosy-colony","sprout-aries","cyan-bestseller","humorous-plywood","heavy-beauty","spiral-riverbed","gifted-income","lead-kiwi","pointed-catshark","ninth-ocean","purple-toucan","tundra-cut","coal-geography","icy-lunaria","agate-wildcat","respected-garlic","polar-almandine","periodic-narcissus","carbonated-waiter","lavish-breadfruit","confirmed-brand","repeated-period"]
You can control separator with the a query-string parameter of separator. i.e, separator=@ , e.g. https://friendly-project-name.kinlan.now.sh/api/names?separator=@
["handsomely@asterisk"]
A very useful aspect of this project is that if a combination of words tends towards being offensive, it is easy to update the Glitch repo to ensure that it doesn't happen again.
Assuming that the project hosting doesn't get too expensive I will keep the service up, but feel free to clone it yourselves if you ever want to create a similar micro-service.
Live example
What follows is a super quick example of the API in action.
const render = (promise, elementId) => {
promise.then(async(response) => {
const el = document.getElementById(elementId);
el.innerText = await response.text();
})
};
onload = () => {
render(fetch("https://friendly-project-name.kinlan.now.sh/api/names"), "basic");
render(fetch("https://friendly-project-name.kinlan.now.sh/api/names?count=100"), "many");
render(fetch("https://friendly-project-name.kinlan.now.sh/api/names?separator=@"), "separator");
}
Single response
Many resposnses
Custom separators
Frankie and Bennys: Pay for your meal via the web
Frankie & Benny's offers a web-based payment system accessible via QR code, eliminating the need for a dedicated app. I tested the process, and while the Google Pay option encountered a glitch (already reported), the overall experience was smooth and efficient, taking about a minute to complete. Read More