
Editor.js — 🔗
I've updated by Hugo based editor to try and use EditorJS as, well, the editor for the blog.
Workspace in classic editors is made of a single contenteditable element, used to create different HTML markups. Editor.js workspace consists of separate Blocks: paragraphs, headings, images, lists, quotes, etc. Each of them is an independent contenteditable element (or more complex structure) provided by Plugin and united by Editor's Core.
I think it works.
I struggled a little bit with the codebase, the examples all use ES Modules, however the NPM dist is all output in IIFE ES5 code. But once I got over that hurdle it has been quite easy to build a UI that looks a bit more like medium.
I lead the Chrome Developer Relations team at Google.
We want people to have the best experience possible on the web without having to install a native app or produce content in a walled garden.
Our team tries to make it easier for developers to build on the web by supporting every Chrome release, creating great content to support developers on web.dev, contributing to MDN, helping to improve browser compatibility, and some of the best developer tools like Lighthouse, Workbox, Squoosh to name just a few.
I love to learn about what you are building, and how I can help with Chrome or Web development in general, so if you want to chat with me directly, please feel free to book a consultation.
I'm trialing a newsletter, you can subscribe below (thank you!)




Quick Logcat - debugging android from the web — 🔗
I was on the flight to Delhi this last week and I wanted to be able to debug my KaiOS device with Chrome OS - I never quite got to the level that I needed for a number of reasons (port forwarding didn't work - more on that in another post), but I did get to build a simple tool that really helps me build for the web on Android based devices.
I've been using WebADB.js for a couple of side projects, but I thought I would at least release one of the tools I made last week that will help you if you ever need to debug your Android device and you don't have adb installed or any other Android system tools.
Quick LogCat is just that. It can connect to any Android device that is in developer mode and has USB enabled, is connected to your machine over USB and most importantly you grant access from the web page to connect to the device, and once that is all done it just runs adb shell logcat to create the following output.
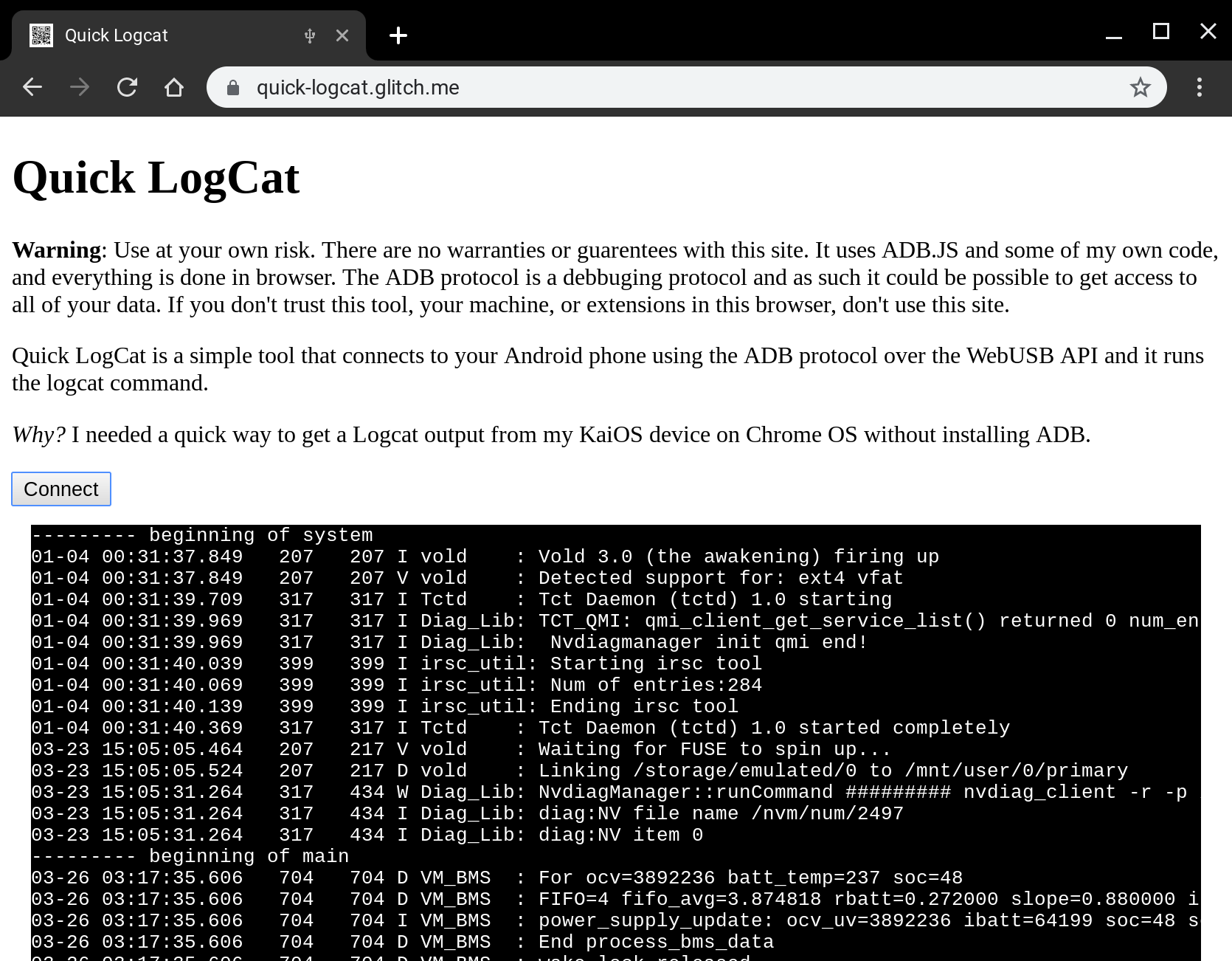
Checkout the source over on my github account, specifically the logger class that has the brunt of my logic - note a lot of this code is incredibly similar to the demo over at webadb.github.io, but it should hopefully be relatively clear to follow how I interface with the WebUSB API (which is very cool). The result is the following code that is in my index file: I instantiate a controller, connect to the device which will open up the USB port and then I start the logcat process and well, cat the log, via logcat.
It even uses .mjs files :D
<script type="module">
import LogcatController from "/scripts/main.mjs";
onload = () => {
const connect = document.getElementById("connect");
const output = document.getElementById("output");
let controller = new LogcatController();
connect.addEventListener("click", async () => {
await controller.connect();
controller.logcat((log) => {
output.innerText += log;
})
});
};
</script>
ADB is an incredibly powerful protocol, you can read system files, you can write over personal data and you can even easily side-load apps, so if you give access to any external site to your Android device, you need to completely trust the operator of the site.
This demo shows the power and capability of the WebUSB API, we can interface with hardware without any natively installed components, drivers or software and with a pervasive explicit user opt-in model that stops drive-by access to USB components.
I've got a couple more ideas up my sleeve, it will totally be possible to do firmware updates via the web if you so choose. One thing we saw a lot of in India was the ability side-load APK's on to user's new phones, whilst I am not saying we must do it, a clean web-interface would be more more preferable to the software people use today.
What do you think you could build with Web USB and adb access?
Debugging Web Pages on the Nokia 8110 with KaiOS
Debugging web pages on the Nokia 8110 (KaiOS) can be tricky due to the lack of traditional developer tools. This post outlines the steps I used to successfully debug, involving enabling Developer Mode on the phone, forwarding a port using adb, and connecting to the phone's runtime via Firefox 48's Web IDE. Read More
Object Detection and Augmentation — 🔗
I've been playing around a lot with the [Shape Detection
API](https://paul.kinlan.me/face-detection/
https://paul.kinlan.me/barcode-detection/
https://paul.kinlan.me/detecting-text-in-an-image/) in Chrome a lot and I really
like the potential it has, for example a very simple QRCode
detector I wrote a long time ago has a JS polyfill, but
uses new BarcodeDetector() API if it is available.
You can see some of the other demo's I've built here using the other capabilities of the shape detection API: Face Detection,Barcode Detection and Text Detection.
I was pleasantly surprised when I stumbled across Jeeliz
at the weekend and I was incredibly impressed at the performance of their
toolkit - granted I was using a Pixel3 XL, but detection of faces seemed
significantly quicker than what is possible with the FaceDetector API.

It got me thinking a lot. This toolkit for Object Detection (and ones like it) use API's that are broadly available on the Web specifically Camera access, WebGL and WASM, which unlike Chrome's Shape Detection API (which is only in Chrome and not consistent across all platforms that Chrome is on) can be used to build rich experiences easily and reach billions of users with a consistent experience across all platforms.
Augmentation is where it gets interesting (and really what I wanted to show off in this post) and where you need middleware libraries that are now coming to the platform, we can build the fun snapchat-esque face filter apps without having users install MASSIVE apps that harvest huge amount of data from the users device (because there is no underlying access to the system).
Outside of the fun demos, it's possible to solve very advanced use-cases quickly and simply for the user, such as:
- Text Selection directly from the camera or photo from the user
- Live translation of languages from the camera
- Inline QRCode detection so people don't have to open WeChat all the time :)
- Auto extract website URLs or address from an image
- Credit card detection and number extraction (get users signing up to your site quicker)
- Visual product search in your store's web app.
- Barcode lookup for more product details in your stores web app.
- Quick cropping of profile photos on to people's faces.
- Simple A11Y features to let the a user hear the text found in images.
I just spent 5 minutes thinking about these use-cases — I know there are a lot more — but it hit me that we don't see a lot of sites or web apps utilising the camera, instead we see a lot of sites asking their users to download an app, and I don't think we need to do that any more.
Update Thomas Steiner on our team mentioned in our team Chat that it sounds
like I don't like the current ShapeDetection API. I love the fact that this
API gives us access to the native shipping implementations of the each of the
respective systems, however as I wrote in The Lumpy Web, Web
Developers crave consistency in the platform and there are number of issues with
the Shape Detection API that can be summarized as:
- The API is only in Chrome
- The API in Chrome is vastly different on every platforms because their
underlying implementations are different. Android only has points for
landmarks such as mouth and eyes, where macOS has outlines. On Android the
TextDetectorreturns the detected text, where as on macOS it returns a 'Text Presence' indicator... This is not to mention all the bugs that Surma found.
The web as a platform for distribution makes so much sense for experiences like these that I think it would be remiss of us not to do it, but the above two groupings of issues leads me to question the long-term need to implement every feature on the web platform natively, when we could implement good solutions in a package that is shipped using the features of the platform today like WebGL, WASM and in the future Web GPU.
Anyway, I love the fact that we can do this on the web and I am looking forwards to seeing sites ship with them.
Got web performance problems? Just wait... — 🔗
I saw a tweet by a good chum and colleague, Mariko, about testing on a range of low end devices keeping you really grounded.
The context of the tweet is that we are looking at what Web Development is like when building for users who live daily on these classes of devices.
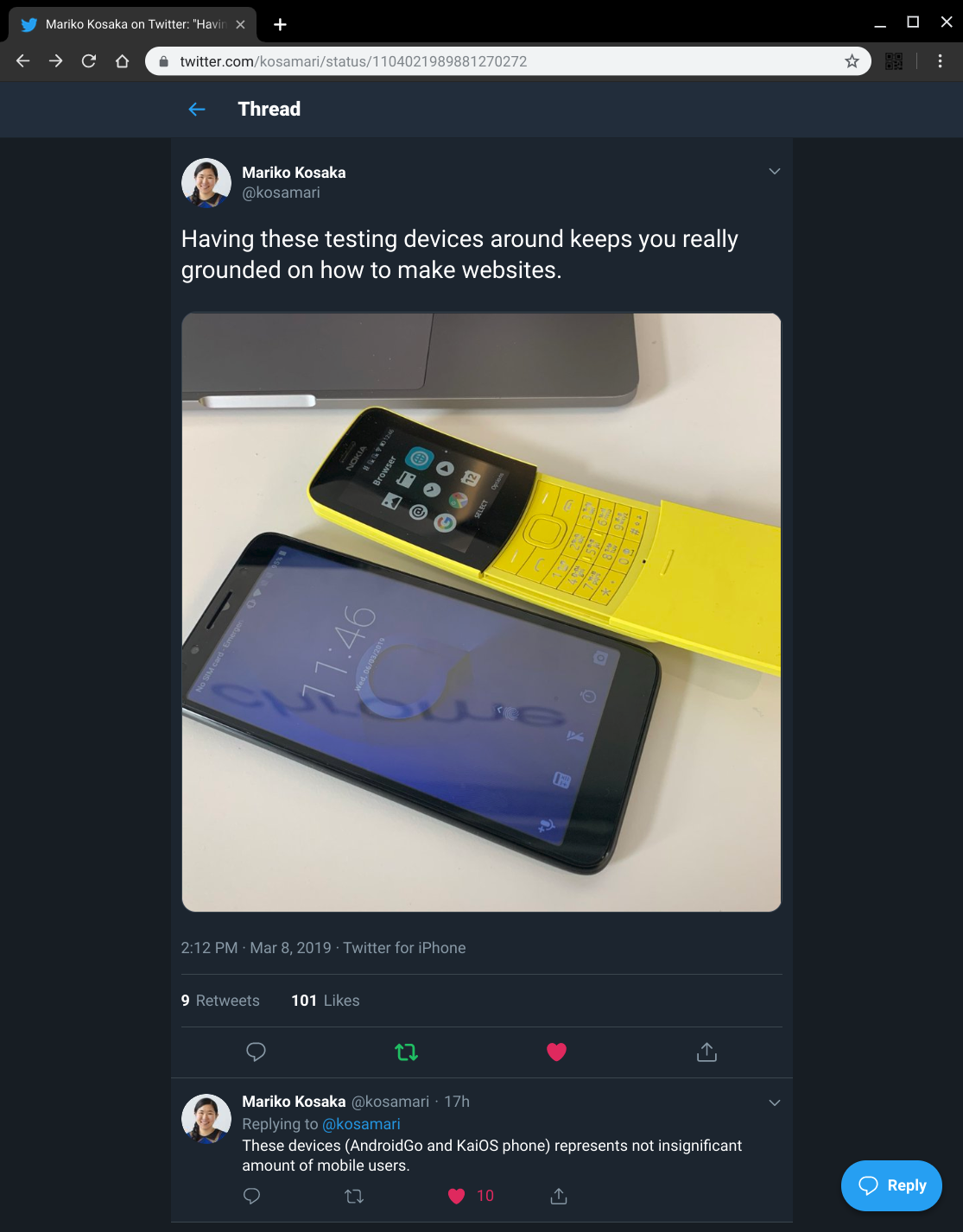
The team is doing a lot of work now in this space, but I spent a day build a site and it was incredibly hard to make anything work at a even slightly reasonable level of performances - here are some of the problems that I ran into:
- Viewport oddities, and mysterious re-introduction of 300ms click-delay (can work around).
- Huge repaints of entire screen, and it's slow.
- Network is slow
- Memory is constrained, and subsequent GC's lock the main thread for multiple seconds
- Incredibly slow JS execution
- DOM manipulation is slow
For many of the pages I was building, even on a fast wifi connection pages took multiple seconds to load, and subsequent interactions were just plain slow. It was hard, it involved trying to get as much as possible off the main thread, but it was also incredibly gratifying at a technical level to see changes in algorithms and logic that I wouldn't have done for all my traditional web development, yield large improvements in performance.
I am not sure what to do long-term, I suspect a huge swathe of developers that we work with in the more developed markets will have a reaction 'I am not building sites for users in [insert country x]', and at a high-level it's hard to argue with this statement, but I can't ignore the fact that 10's of millions of new users are coming to computing each year and they will be using these devices and we want the web to be the platform of choice for content and apps lest we are happy with the rise of the meta platform.
We're going to need to keep pushing on performance for a long time to come. We will keep creating tools and guidance to help developers load quickly and have smooth user interfaces :)
Browser Bug Searcher — 🔗
I was just reflecting on some of the work our team has done and I found a project from 2017 that Robert Nyman and Eric Bidelman created. Browser Bug Searcher!.
It's incredible that with just a few key presses you have a great overview of your favourite features across all the major browser engines.
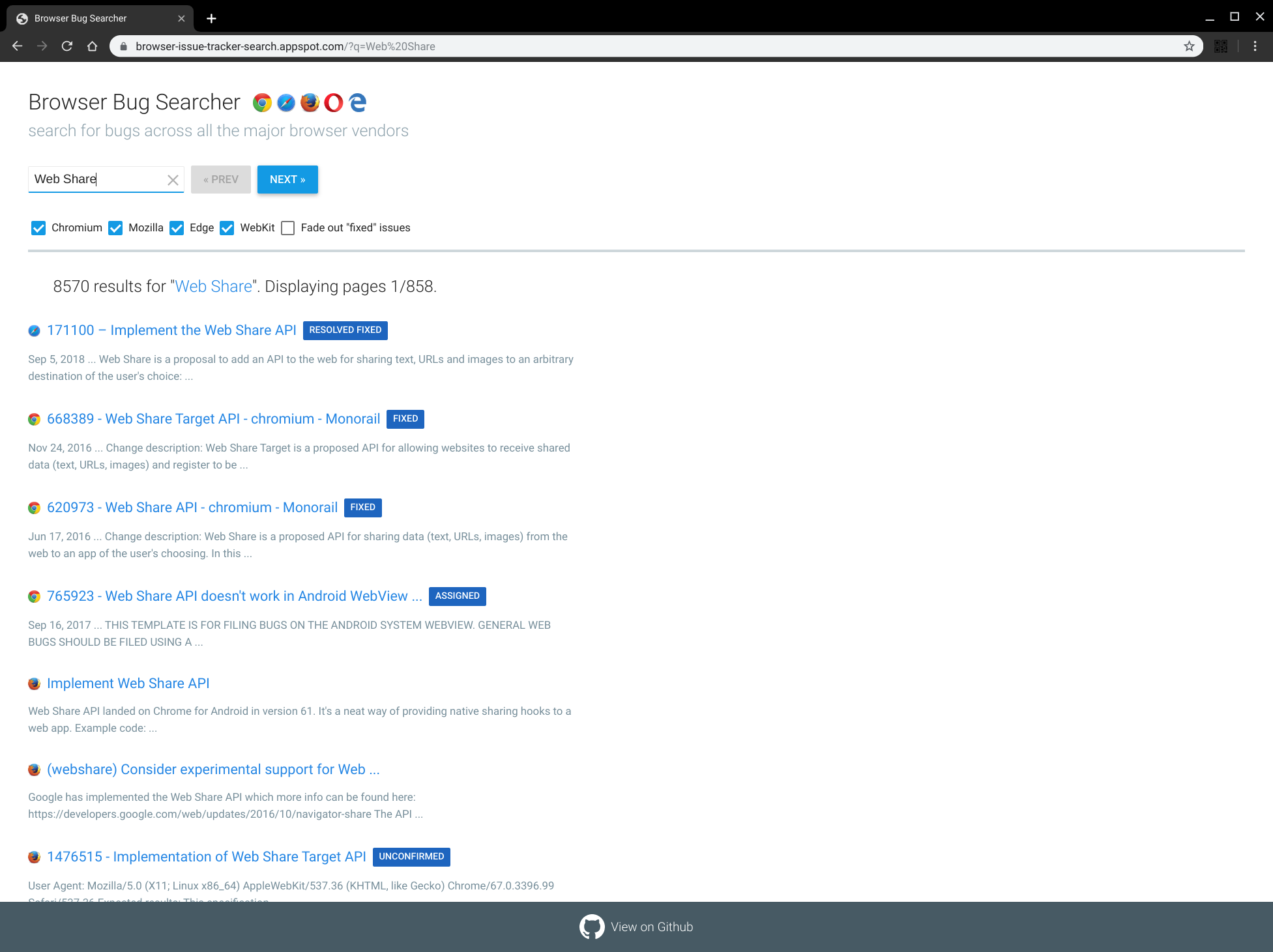
This actually highlights one of the issues that I have with crbug and webkit bug trackers, they don't have a simple way to get feeds of data in formats like RSS. I would love to be able to use my topicdeck aggregator with bug categories etc so I have a dashboard of all the things that I am interested in based on the latest information from each of the bug trackers.
Github's Web Components — 🔗
I was looking for a quick markdown editor on https://www.webcomponents.org/ so that I can make posting to this blog easier and I stumbled across a neat set of components by github.
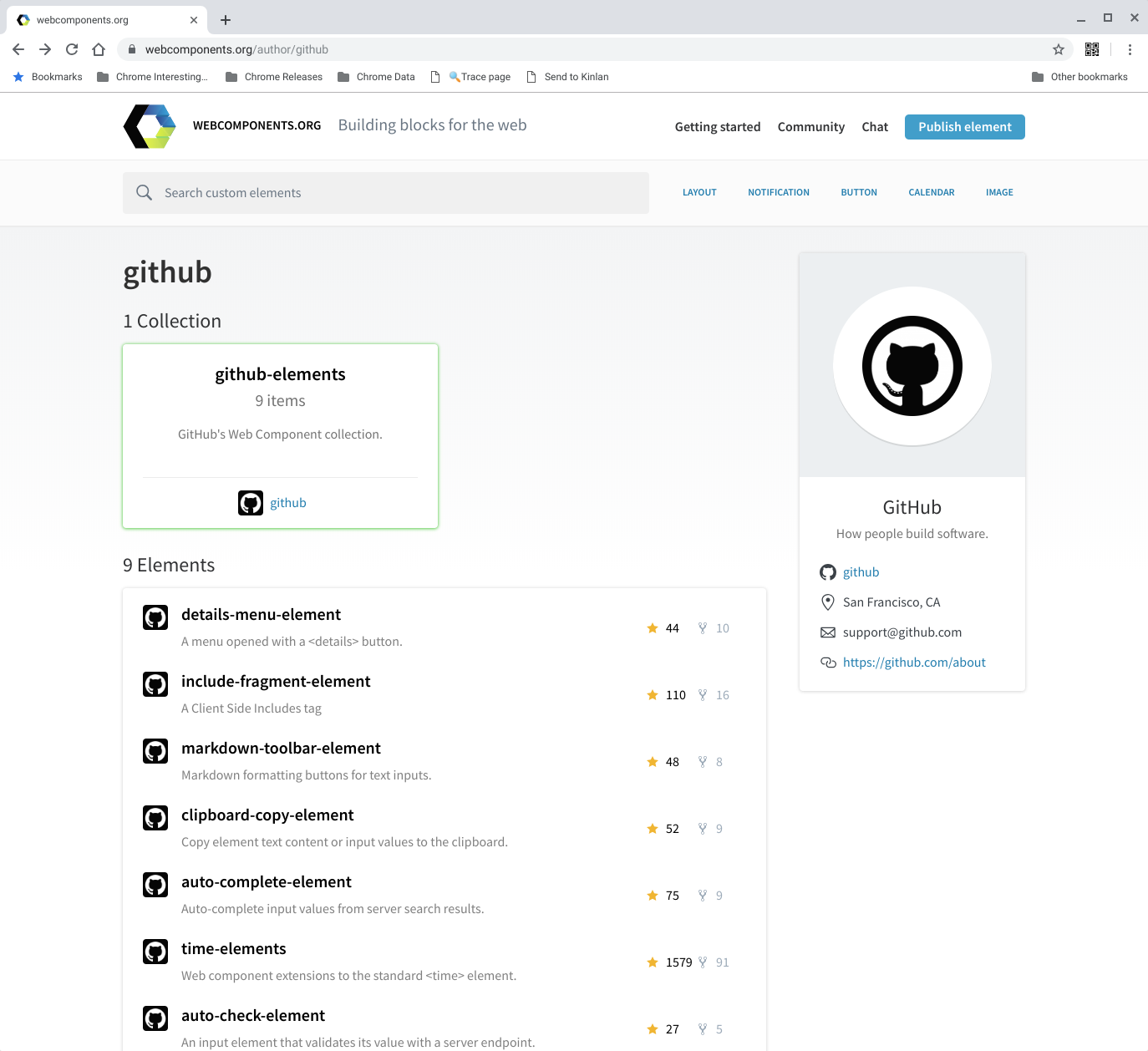
I knew that they had the <time-element> but I didn't know they had a such a nice and simple set of useful elements.
London from Kingscross
A quick photo of the London skyline from near Kings Cross station. The weather is looking up! Read More
The GDPR mess
The implementation of GDPR consent across the industry is flawed and confusing. Many consent mechanisms offer choices that seem meaningless, as users often can't discern the actual impact of their selection. For example, the difference between accepting all cookies and using only necessary cookies is often unclear, both in terms of functionality and verifiability. Read More
Brexit: History will judge us all — 🔗

History will judge us all on this mess, and I hope it will be a case study for all on the effects of nationalism, self-interests, colonial-hubris, celebrity-bafoonery.
Fuckers.
File Web Share Target
The File Web Share Target API is a new, powerful feature in Chrome Canary that allows web apps to receive files (like images) shared from other apps, much like native apps. This post details how I implemented this API on my blog, enabling direct image uploads from my Android camera app. The process involves declaring support for file sharing in your web app manifest and handling the incoming file data in a service worker. The API uses a progressive approach, leveraging standard form POST requests, making integration relatively simple. This feature significantly enhances web app integration with the host operating system, closing the gap between web and native apps. Read More
Testing-file-share-target-from-camera
I successfully tested sharing a photo directly from the camera app to another app. Check it out! Read More
testing-file-share-target
This blog post is a test of the Android Share Target API and its file sharing capabilities. If the image displays successfully, the test is considered successful. Read More
Ricky Mondello: Adoption of Well-Known URL for Changing Passwords — 🔗
Ricky Mondello over on the Safari team just recently shared a note about how Twitter is using the ./well-known/change-password spec.
I just noticed that Twitter has adopted the Well-Known URL for Changing Passwords! Is anyone aware of other sites that have adopted it?
Twitter's implementation: https://twitter.com/.well-known/change-password Github's: https://github.com/.well-known/change-password Specification :https://github.com/WICG/change-password-url
The feature completely passed me by but it is a neat idea: given a file in a well-known location, can the browser offer a UI to the user that allows them to quickly reset their password without having to navigate the sites complex UI..
The spec is deceptively simple: the well-known file simply contains the URL to direct the user to when they want to perform the action. This lead me in to thinking, can we offer more of these features:
- A well known location for GDPR-based consent models (cookie consent) - site owners could offer a link to the page where a user can manage and potentially revoke all cookies and other data consent items.
- A well known location for browser permission management - site owners could offer a quick place for users to be able to revoke permissions to things like geo-location, notifications and other primitives.
- A well known path for account deletion and changes
- A well known path for mailing list subscription management
The list goes on.... I really like the idea for simple redirect files to help users to discover common user actions, and for a way for the browser to surface it up.
Update: I added an issue to Chrome to see if we can get a similar implementation.
pinch-zoom-element — 🔗
Jake and the team built this rather awesome custom element for managing pinch zooming on any set of HTML outside of the browser's own pinch-zoom dynamics (think mobile viewport zooming). The element was one of the central components that we needed for the squoosh app that we built and released at Chrome Dev Summit (... I say 'released at Chrome Dev Summit' - Jake was showing it to everyone at the China Google Developer Day even though the rest of the team were under embargo ;) ... )
install:
npm install --save-dev pinch-zoom-element<pinch-zoom> <h1>Hello!</h1> </pinch-zoom>
I just added it to my blog (took just a couple of minutes), you can check it out on my 'life' section where I share photos that I have taken. If you are on a touch-enabled device you can quickly pinch-zoom on the element, if you are using a track-pad that can handle multiple finger inputs that works too.
This element is a great example of why I love web components as a model for creating user-interface components. The pinch-zoom element is just under 3kb on the wire (uncompressed) and minimal dependencies for building and it just does one job exceptionally well, without tying any custom application-level logic that would make it hard to use (I have some thoughts on UI logic vs App logic components that I will share based on my learning's from the Squoosh app).
I would love to see elements like these get more awareness and usage, for example I could imagine that this element could replace or standardise the image zoom functionality that you see on many commerce sites and forever take away that pain from developers.
Registering as a Share Target with the Web Share Target API — 🔗
Pete LePage introduces the Web Share Target API and the the availability in Chrome via an origin trial
Until now, only native apps could register as a share target. The Web Share Target API allows installed web apps to register with the underlying OS as a share target to receive shared content from either the Web Share API or system events, like the OS-level share button.
This API is a game changer on the web, it opens the web up to something that was only once available to native apps: Native Sharing. Apps are silos, they suck in all data and make it hard to be accessible across platforms. Share Target starts to level the playing field so that the web can play in the same game.
The Twitter Mobile experience has Share Target already enabled. This post was created using the Share Target I have defined in my sites 'admin panel' manifest.json - it works pretty well, and the minute they land file support I will be able to post any image or blob on my device to my blog.
Very exciting times.
Read the linked post to learn more about the time-lines for when this API should go live and how to use the API.
Why Build Progressive Web Apps: Push, but Don't be Pushy! Video Write-Up — 🔗
A great article and video and sample by Thomas Steiner on good push notifications on the web.
A particularly bad practice is to pop up the permission dialog on page load, without any context at all. Several high traffic sites have been caught doing this. To subscribe people to push notifications, you use the the PushManager interface. Now to be fair, this does not allow the developer to specify the context or the to-be-expected frequency of notifications. So where does this leave us?
Web Push is an amazingly powerful API, but it's easy to abuse and annoy your users. The bad thing for your site is that if a user blocks notifications because you prompt without warning, then you don't get the chance to ask again.
Treat your users with respect, Context is king for Web Push notifications.
Maybe Our Documentation "Best Practices" Aren''t Really Best Practices — 🔗
Kayce Basques, an awesome tech writer on our team wrote up a pretty amazing article about his experiences measuring how well existing documentation best-practices work for explaining technical material. Best practices in this sense can be well-known industry standards for technical writing, or it could be your own companies writing style guide. Check it out!
Recently I discovered that a supposed documentation "best practice" may not actually stand up to scrutiny when measured in the wild. I'm now on a mission to get a "was this page helpful?" feedback widget on every documentation page on the web. It's not the end-all be-all solution, but it's a start towards a more rigorous understanding of what actually makes our docs more helpful.
Whilst I am not a tech writer, my role involves a huge amount of engagement with our tech writing team as well as also publishing a lot of 'best practices' for developers myself. I was amazed by how much depth and research Kayce has done on the art of writing modern docs through the lens of our teams content. I fully encourage you to read Kayce's article in-depth - I learnt a lot. Thank you Kayce!
Feature Policy & the Well-Lit Path for Web Development (Chrome Dev Summit 2018) — 🔗
Jason did an amazing talk about a little-known but new area of the web platform 'Feature Policy'.
Feature Policy is a new primitive which allows developers to selectively enable, disable, and modify the behaviour of certain APIs and features in the browser. It's like CSP, but for features & APIs! Teams can use new tools like Feature Policy and the Reporting API to catch errors before they grow out of control, ensure site performance stays high, keep code quality healthy, and help avoid the web's biggest footguns.
Check out featurepolicy.rocks for more information about Feature Policy, code samples, and live demos.
Submit new ideas for policies or feedback on existing policies at → https://bit.ly/2B3gDEU.
To learn more about the Reporting API see https://bit.ly/rep-api.
Feature policy is an interesting area that can seem like a hard place to work out where.
There are a couple of areas where I seeing it being beneficial:
- Control 3rd-party content. As an embedder, you should be able to control what functionality runs in the context of your page and when it runs. Feature policy gives you that control. Don't want iframes to autoplay video? Turn it off. Don't want third party iframes to request geo-location? Turn it off. Don't want iframes to access sensor information? Turn it off. You should be in control of your experience, not third party sites.
- Stay on target in development. We talked a lot at Chrome DevSummit about perf-budgets, yet today they can be hard to reason with. Feature Policy enabled on your development and staging services will help you know if any sets of changes you are making will breach your performance budgets by stopping you from doing the wrong thing. A case in point, our very own Chrome Dev Summit side had feature policy enabled for images called 'max-downscaling-image' - it inverts the colour of the image when it has been downscaled too much (a large image displayed in a small container). Feature policy picked it up and enabled us to make a decision about what to do. In the end, we disabled the policy because we were using the larger version of the image in multiple places and the images were already cached at that point.
I do encourage you all to look in to feature policy a lot more because it will play an important part of the future of the web. If you want to see the latest Policies that Chrome is implementing then checkout Feature Policy on Chrome Status
Photos from Chrome Chrome Dev Summit 2018 — 🔗
Some awesome photos from this years Chrome Dev Summit
I love this event ;)
I am like Wally - if you can find me, you get a sticker.