
The work that led to this is a research project that I will soon publish on aifoc.us, where I am analysing if the presence of a URL in a prompt influences the output based on the latent "knowledge" about that URL in the model. While doing this project I needed to test a heap of URLs and see if their data was in the model or not and I hit on a heap of problems. The more time I spent in that data, the more I realised I couldn't answer a basic question about a large share of the traffic fetching those URLs: when one of the many agents, indexers, and scrapers loads a page, what does it actually do? Download the HTML and stop? Parse the CSS? Follow the font linked from inside that CSS? Can they run the JavaScript, or just fetch the .js file and move on?
So I built ua-tracer to answer it, and it's a tool that I think will be useful for many web developers trying to understand what any browser or bot does when it accesses your site.
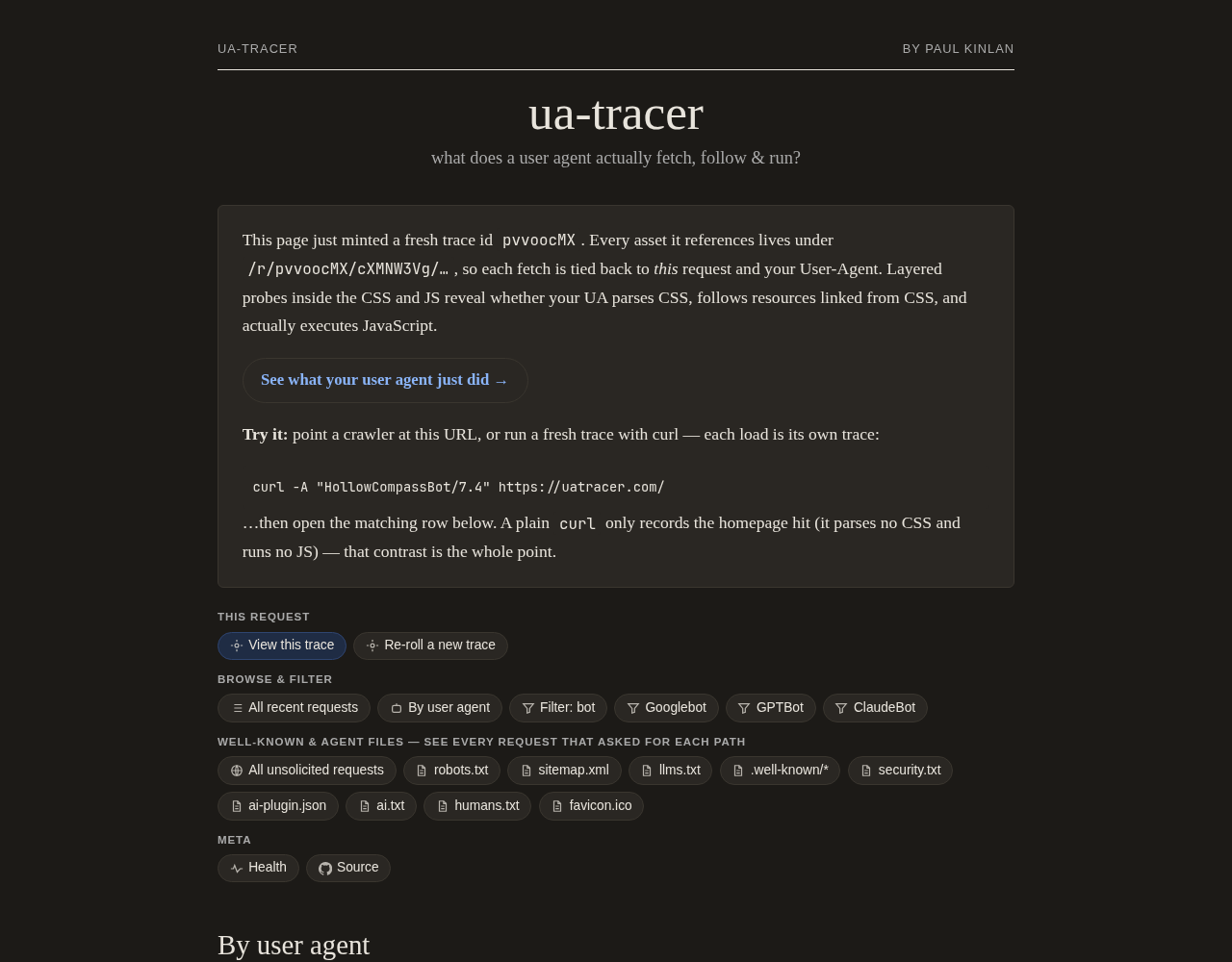
Click through any row in that list and you land on the trace detail, a request-by-request account of what that one user agent did:
How it works
Every time a user agent loads https://uatracer.com/, the site mints a unique trace id and a per-request secret, and renders a page whose every asset (stylesheet, script, images, font, manifest) carries both in its path. The secret is private to that one page load, so only the agent that received the HTML can fetch the probe assets: no guessing, no replay by anyone else.
/r/{id}/{secret}/style.css the real stylesheet
/r/{id}/{secret}/main.js the real script
/r/{id}/{secret}/photo.png a real PNG
/r/{id}/{secret}/font.woff2 a real woff2 font
Because the id is unique per page load, every later asset request can be tied back to the exact homepage hit and the user agent that made it. I also added other probes that come what those assets themselves reference (paths below drop the {secret} segment for readability):
| Probe | Referenced from | Hitting it proves… |
|---|---|---|
/r/{id}/{secret}/css-bg.png |
a background-image: inside style.css |
the UA parsed the CSS and followed a URL inside it |
/r/{id}/{secret}/css-font.woff2 |
an @font-face { src: } inside style.css |
the UA resolved a CSS font source |
/r/{id}/{secret}/manifest-icon.png |
icons[].src inside manifest.json |
the UA parsed the manifest and followed an icon |
/r/{id}/{secret}/js-ran.gif |
new Image().src = … in main.js, at runtime |
the UA executed classic JS |
/r/{id}/{secret}/module-ran.gif |
a runtime beacon in an ES module | the UA executed an ES module |
/r/{id}/{secret}/timing |
a POST of performance.getEntriesByType('resource') |
a real engine ran and produced a client-side waterfall |
A plain downloader (think curl) nomrally just fetches the HTML and stops. A CSS-aware fetcher additionally hits css-bg.png and css-font.woff2. A UA that parses the manifest reaches manifest-icon.png etc. Social unfurlers (Twitterbot, Discordbot etc) fetch the social-card image. Finally, only a user agent that runs JavaScript will ever touch js-ran.gif or post to /timing.
What a trace looks like
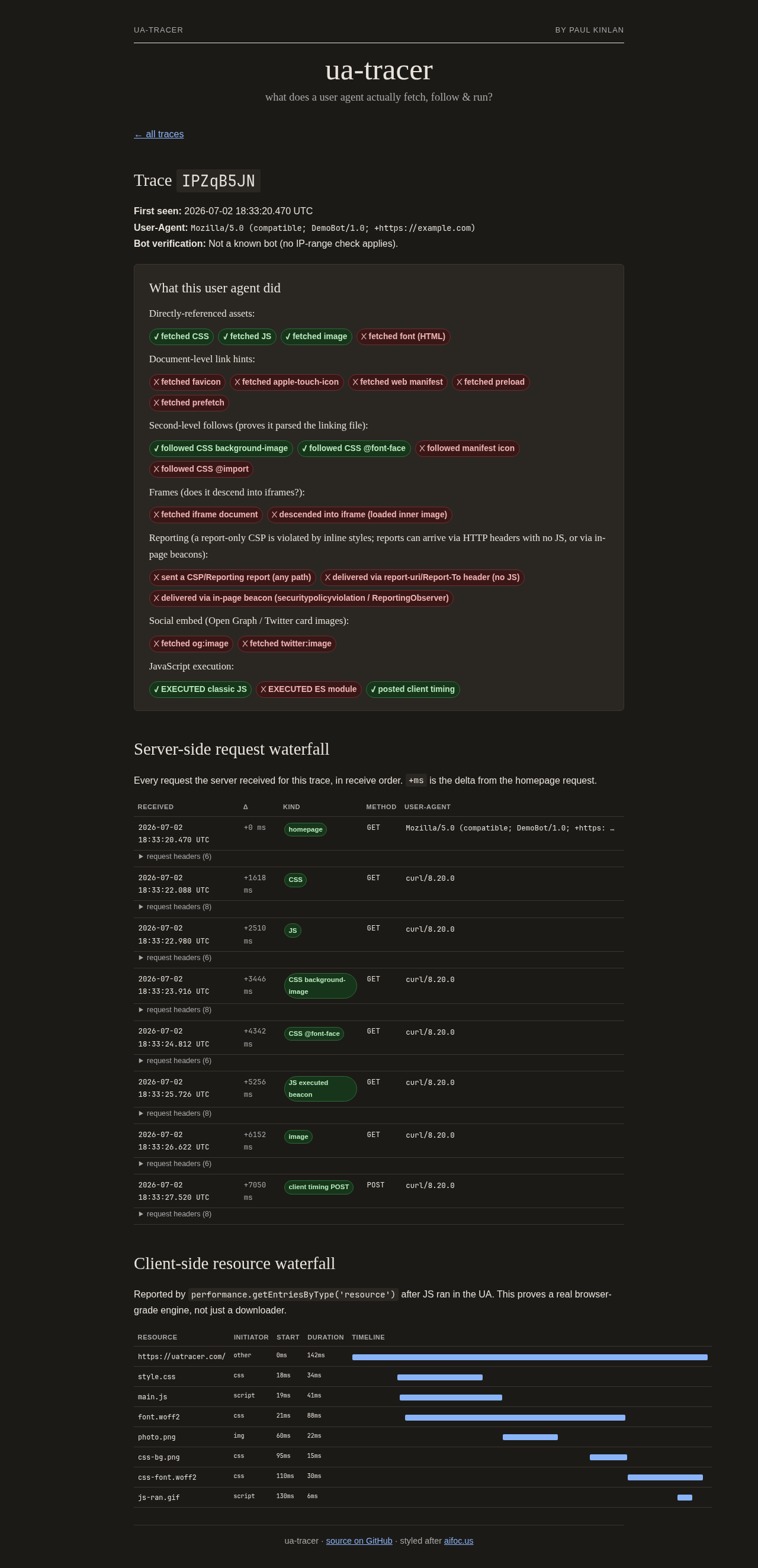
Open any trace and you get a request-by-request account of how far the agent went: which asset types it fetched, whether it followed the CSS-linked resources, whether it executed JavaScript, and the client-side resource-timing waterfall it posted back if it did.
This particular trace is synthetic: I generated it by pointing a made-up user agent at the site and walking it through the assets by hand:
curl -A "Mozilla/5.0 (compatible; DemoBot/1.0; +https://example.com)" https://uatracer.com/
# then fetch the trace-scoped assets it references:
curl https://uatracer.com/r/{id}/{secret}/style.css
curl https://uatracer.com/r/{id}/{secret}/js-ran.gif # the JS-execution beacon
The trace detail is intentionally public: share /trace/{id} as a link and anyone can read the result, which makes it easy to pass a finding along ("look, this agent doesn't run JS").
Some early analysis on what the bots actually do
This site hasn't been live that long so it's not got heaps of data yet (hence this post to try and raise some awareness), but I've got some insights that I think are interesting.
One caveat first: a User-Agent string is trivially spoofable. The tool also checks each request's source IP against the CIDR ranges its operator publishes. Every major crawler operator now publishes a list you can match against: Google, OpenAI's GPTBot and OAI-SearchBot, Bing, and Anthropic's ClaudeBot (IP list). So a "Googlebot" or "ClaudeBot" trace is either verified (the IP is in the operator's published range) or flagged as likely spoofed. The one exception in the data so far is OpenAI's ChatGPT-User, which is triggered by a person rather than run on a schedule and publishes no fixed ranges, so its User-Agent alone can't be confirmed.
Bots from the same company do not behave alike. OpenAI seems to run at least three agents against the site (all IP-verifiable), and each does something different:
- GPTBot (
+openai.com/gptbot) fetches every directly-referenced asset and parses the stylesheet, following thebackground-image, the@font-facesource, and the@import. It does not run JavaScript. - OAI-SearchBot (
+openai.com/searchbot) presents a full Mac Chrome User-Agent and runs JavaScript: it executed both the classic script and the ES module, and followed the CSS background image. Of the OpenAI agents, this one is browser-grade. - ChatGPT-User (
+openai.com) fetches the page and its assets but runs no JavaScript and parses no CSS.
Anthropic's ClaudeBot (+claudebot@anthropic.com) fetches the full asset set like GPTBot, but stops at the CSS file: it never reaches the background-image or @font-face inside it, and it does not run JavaScript. So "an AI is reading my page" breaks three different ways depending on whether that AI is GPTBot, OAI-SearchBot, or ClaudeBot. (ClaudeBot traces · GPTBot traces · all bots)
Googlebot is documented to render JavaScript in a second pass (Google's JavaScript SEO docs describe crawl → render queue → a headless Chromium executing the script later). I have not caught that render pass in the traces yet; what I have seen is the fetch-only first stage. So "Googlebot doesn't run JS" would be the wrong conclusion to draw, and the tool is set up to record the second stage if and when it arrives.
Some bots announce their intent; most don't. DomainArrivalsBot/0.1 identifies itself as either (+homepage-extract; research) or (+homepage-only; research), telling you in the UA string whether it takes the whole page or just the root. That honesty is rare. Most agents either masquerade as browsers with full Mozilla/AppleWebKit strings (OAI-SearchBot above is a textbook case) or skip the courtesy entirely: okhttp/5.3.0 and Go-http-client/1.1 between them account for dozens of visits, and both are raw HTTP libraries with no name.
This is the data I wanted for aifoc.us and couldn't get from any log. The bots reading the web are not one thing; they are a population, and the only way to know what a given one does is to watch it. We can measure page views to the nearest second; we still can't tell whether the thing reading the page ran the code on it.
Try it
The site is at uatracer.com. Open it in a browser to mint your own trace, or point a crawler at it. The source is on GitHub: a single Deno file and a Deno KV database, nothing more. (note - I've used an agent to build this out)
I'd love some feedback on this and if you have any other tests that you would like me to add.
Sources: bot IP ranges and what each operator says
- Google publishes its crawler IP ranges (
common-crawlers.json) and recommends a reverse-DNS check: resolve the IP to agooglebot.comhostname, then forward-resolve it back to the same IP (Verify Googlebot). Googlebot also runs JavaScript in a separate render pass using an evergreen Chromium (JavaScript SEO basics). - OpenAI publishes ranges for GPTBot (
gptbot.json) and OAI-SearchBot (searchbot.json); overview at platform.openai.com/docs/bots. ChatGPT-User is triggered by a person and has no fixed ranges. - Bing publishes
bingbot.jsonand a verification guide using reverse-DNS to asearch.msn.comhostname. - Anthropic publishes its crawler IPs at
claude.com/crawling/bots.json, covering ClaudeBot, Claude-User and Claude-SearchBot (help article). Anthropic notes that IP-based blocking "may not work correctly or persistently guarantee an opt-out", but the list is sufficient to confirm a request genuinely originates from Anthropic.