I've had a lot of fun over the holiday period. I spent a huge amount of time with my family, and in some down time I got to hack.
Last week I talked about the Button and Link scraping tool that I created to get the data to train a model that will help me work out if an <a> element looks like a button. I've made a number of updates to that tool based on some of the results from what I am planning to talk about in this post.
This post is about how I trained an ML model to detect if an element is a button or a text link.
I'm still learning a lot, so if you have any feedback or suggestions on how to improve this please leave a comment or message me.
You can play with the model using the Google Colab that I built for this project (well, initially copied from Laurence Moroney.)
The data
I now have a repository of about 3000 images of buttons, and 4000 images of links generated from this list of urls data using the Button and Link scraping tool that I created.
It can be downloaded like so:
dataset_url = "https://github.com/PaulKinlan/button-and-link-scraper/releases/download/latest/images.tgz"
data_dir = tf.keras.utils.get_file(origin=dataset_url,
fname="images",
untar=True)
data_dir = pathlib.Path(data_dir)
Which is output into two directories, which can then be loaded into two a training and validation data set.
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.4,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.4,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Each image in the training and validation set are scaled to a 256x256 image to keep things uniform for the model.
The model
If you are familiar with ML training, you can look at the Colab that I have created. In terms of ML, it's relatively standard. A convolution network with three layers that spits has two classes: button or text link
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=[img_height, img_width, 1]),
tf.keras.layers.GaussianNoise(0.01),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_classes) # activation='softmax' ??
])
One interesting thing, I added some noise to the training data as I found it gave me better results for images the model has never seen before (but more on that later).
Overall, the training and validation numbers are good (well, a little too good).
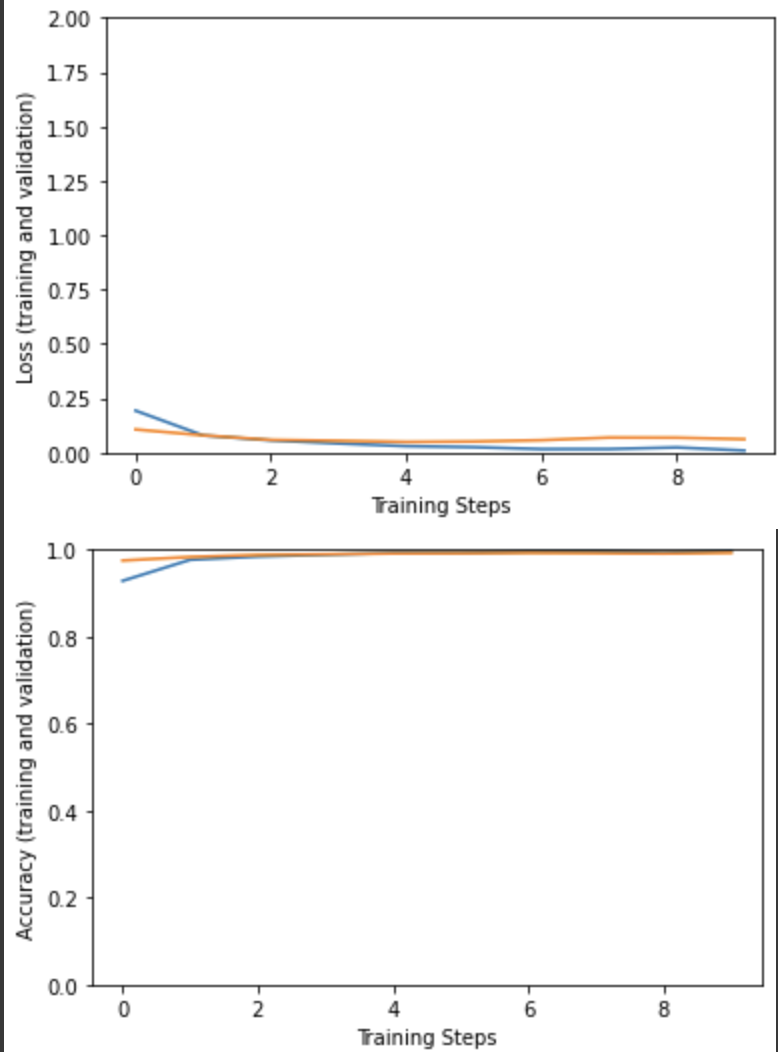
I need to work out if my data is varied enough or not, but when I test it against some random images it works pretty well!
Here's a button looking thing:
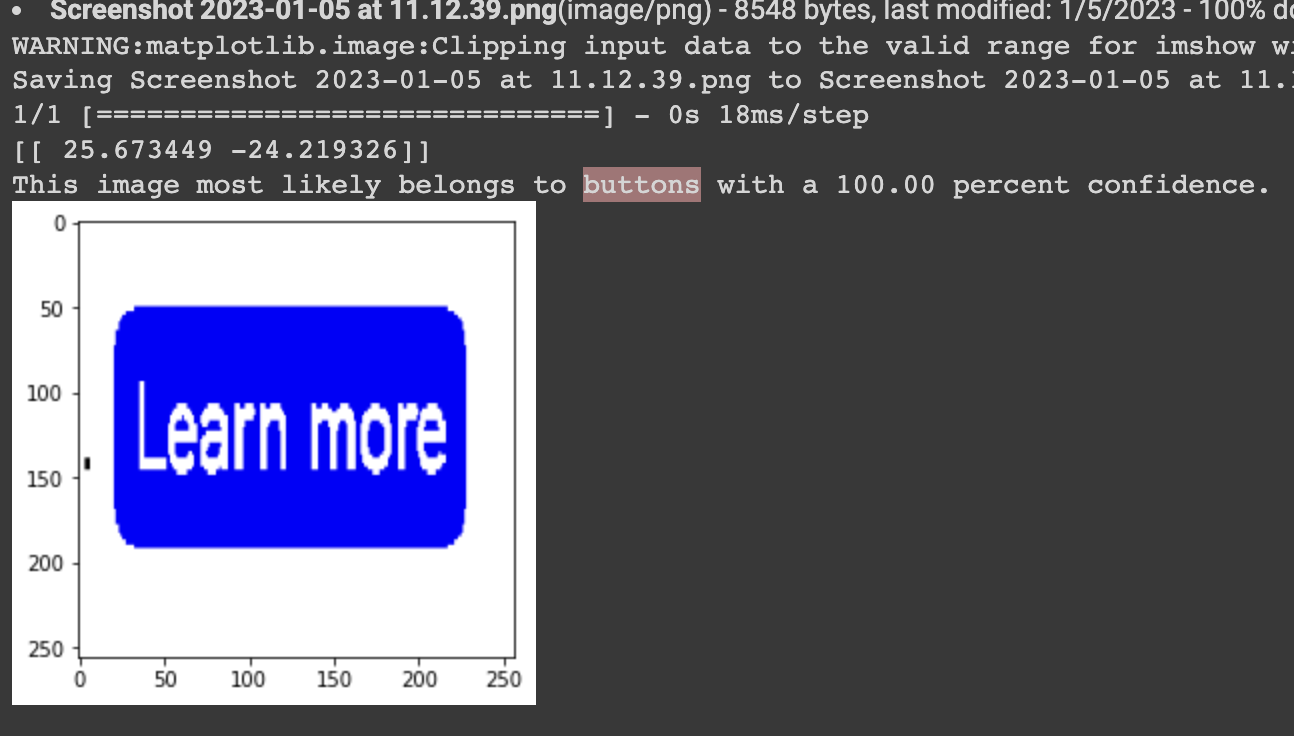
And here is a thing that looks like a link:

It's not perfect, but I'm happy with the result so far.
Things I have learnt
A lot of time went into cleaning up the training data so I ended up doing a number of things to improve the output of the model. I'd like to say a lot of the changes I made were based on insight and experience, however in reality I had to experiment a lot and that was rather time consuming.
I've documented some of the issues that I had so that maybe they will be useful for anyone else that is new to ML and is looking for things to experiment with.
- Early models seemed to classify buttons as links if the colour was different.
Attempt: I first changed randomly changed the hue of all my images, however that massively slowed down training as I wanted to train on the original images and then add in the new hues. It didn't really help with classification.
Best solution so far: Change the image to grayscale using
train_ds = train_ds.map_lambda x, y: (tf.image.rgb_to_grayscale(x), y)), not only is there less data to train on (it seemed to speed up) and the colour vairance became less of an issue because I didn't have to worry about hues as much any more. - The model seems to identify text, specifically when the word "here" or "button" is present. Attempt: The training data is off sites that I own and there is a lot of buttons with the same text. It appears that the feature extraction in the CNN picked this up. Best solution so far: Get better data. I added in a number of sites that that use multiple languages to try and add variety.
- Sometimes the same image button but with a couple of pixels different had a different result.
Attempt 1: Add some random rotations
train_ds = train_ds.map(lambda x, y: (tf.keras.layers.RandomRotation((-0.05, 0.05))(x), y))on images to give some varaiance to the data. This didn't make any difference other than bloat the training set because in the wild there are very very few links or buttons that aren't in landscape orientation. Attempt 2: On inspection of the input data, some images had jpeg compression artifacts so I tried to usetrain_ds = train_ds.map(lambda x, y: (tf.image.adjust_jpeg_quality(x, 75), y))however it no longer returns an image tensor (seems like a bug), so in the link scraper software I now also create a heavily compressed version of the image. This yielded better results. Best solution so far: Added some random noise to all the images. This increased the accuracy of the the validation set and also my testing in the wild. My suspicion is that the variation means it doesn't overfit as much.
Next steps
I've learnt a lot, and while it's still not perfect I want to get this into "production" so that I can see how it holds up with a bit more usage, so I am going to work on two things:
- Build a web app tool to help me test quickly and see if I can get TensorFlow working and help me quickly validate how well it works.
- Build a Lighthouse Audit that will look at the links on a page and create a report.

I lead the Chrome Developer Relations team at Google.
We want people to have the best experience possible on the web without having to install a native app or produce content in a walled garden.
Our team tries to make it easier for developers to build on the web by supporting every Chrome release, creating great content to support developers on web.dev, contributing to MDN, helping to improve browser compatibility, and some of the best developer tools like Lighthouse, Workbox, Squoosh to name just a few.
I love to learn about what you are building, and how I can help with Chrome or Web development in general, so if you want to chat with me directly, please feel free to book a consultation.
I'm trialing a newsletter, you can subscribe below (thank you!)



