
This post wraps up the series of posts I created about applying ML to some developer tasks that are hard to do programatically. Specifically, I wanted to create a tool that would let me detect if an anchor on a page <a> was styled to look like a button or not (woot, it worked!)
You can check out the previous posts here:
And you can check out the code here:
I had a lot of fun relearning a bunch of ML for the this and while I am certainly no expert, what I learnt gave me some confidence for the future in that it is very possible to sensibly integrate ML into many existing products specifically the ability to visually inspect a page and make recommendations about it.
The final step of my project was to create the Lighthouse Audit. The goal of this particular audit is to visually highlight in the final report all of the links that look like a button, like so:
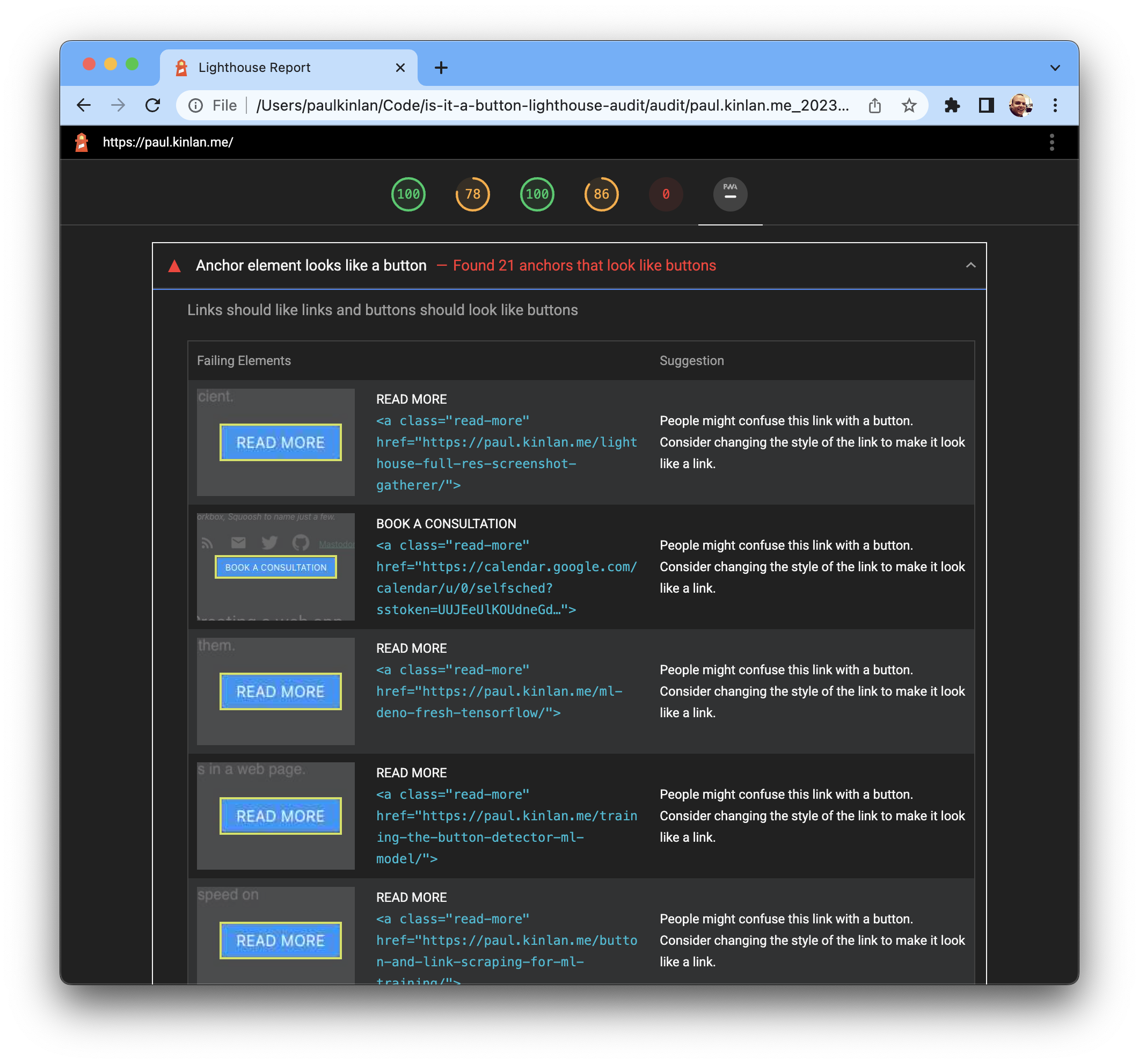
I'm very happy with the result.
You can see from the source here that it is very similar to the web app in that it takes a list of images and runs it through the TensorflowJS model. In fact, the code to run the image through the model is almost exactly the same in both the web app and the lighthouse Audit.
async function testImage(model, image) {
const normalizedData = tf.tidy(() => {
//convert the image data to a tensor
const decodedImage = tf.node.decodePng(image, 1);
const tensor = tf.image.resizeBilinear(decodedImage, [256, 256]);
// Normalize the image
const offset = tf.scalar(255.0);
const normalized = tensor.div(offset);
//We add a dimension to get a batch shape
const batched = normalized.expandDims(0);
return batched;
});
const predTensor = model.predict(normalizedData);
const predSoftmax = predTensor.softmax();
const data = await predSoftmax.data();
const max = Math.max(...data);
const maxIdx = data.indexOf(max);
const classes = {
0: "Button",
1: "Text Link",
};
return { classname: classes[maxIdx], score: max };
}
I loved the Lighthouse Audit API because it worked pretty much as expected. The biggest wrinkle that I had is that the ML model requires clean screenshots of the anchor which means that I have do some extra work. The first is to generate a high-res image of the page because the current "FullscreenShot" artefact is a heavily compressed JPEG screenshot that can't be used in the model, and the second is a list of "NonOccludedAnchorElements" which is used to detect <a> elements in the DOM that are visible and unlikely to be obscured by another element.
static get meta() {
return {
id: "anchor-looks-like-a-button",
title: "Anchor element looks like links",
failureTitle: "Anchor element looks like a button",
description:
"Links should like links and buttons should look like buttons",
requiredArtifacts: [
"AnchorElements",
"NonOccludedAnchorElements",
"BigScreenshot",
],
};
}
And then once the audit is running and I loop through all of the nonOccludedAnchorElements pull them out of the high-res screenshot and pass them through to the ML model via await testImage(newModel, image); as follows.
for (const anchorElement of nonOccludedAnchorElement) {
const { left, top, width, height } = anchorElement.node.newBoundingRect;
const newScreenshot = screenshot.clone().extract({
left: Math.floor(Math.max(left * devicePixelRatio, 0)),
top: Math.floor(Math.max(top * devicePixelRatio,0)),
width: Math.floor(Math.min(width * devicePixelRatio, metadata.width)),
height: Math.floor(Math.min(height * devicePixelRatio, metadata.height)),
});
try {
const image = await newScreenshot.clone().png().toBuffer();
const { classname, score } = await testImage(newModel, image);
// console.log(classname, score, anchorElement.node.lhId);
await newScreenshot
.clone()
.png()
.toFile(`./images/${anchorElement.node.lhId}-${classname}.png`);
if (classname === "Button") {
buttonsOnPage.push(anchorElement);
}
} catch (error) {
console.error(error, left, top, width, height);
}
}
And that's it.
Overall, I think it works well. I would caution that there are a lot of edge cases, for example it's ok sometimes to have an anchor look like a button for certain calls to action and the model can't distinguish that (yet...)
I am bullish because I believe that once hard tasks that require a visual inspection of a page are now a lot more possible with the application of a well trained model and I think this opens up a new set of opportunities for developers.