
I had a little down time after Google IO and I wanted to scratch a long-term itch I've had. I just want to be able to copy text that is held inside images in the browser. That is all. I think it would be a neat feature for everyone.
It's not easy to add functionality directly into Chrome, but I know I can take advantage of the intent system on Android and I can now do that with the Web (or at least Chrome on Android).
Two new additions to the web platform - Share Target Level 2 (or as I like to call it File Share) and the TextDetector in the Shape Detection API - have allowed me to build a utility that I can Share images to and get the text held inside them.
The basic implementation is relatively straight forwards, you create a Share Target and a handler in the Service Worker, and then once you have the image that the user has shared you run the TextDetector on it.
The Share Target API allows your web application to be part of the native sharing sub-system, and in this case you can now register to handle all image/* types by declaring it inside your Web App Manifest as follows.
"share_target": {
"action": "/index.html",
"method": "POST",
"enctype": "multipart/form-data",
"params": {
"files": [
{
"name": "file",
"accept": ["image/*"]
}
]
}
}
When your PWA is installed then you will see it in all the places where you share images from as follows:
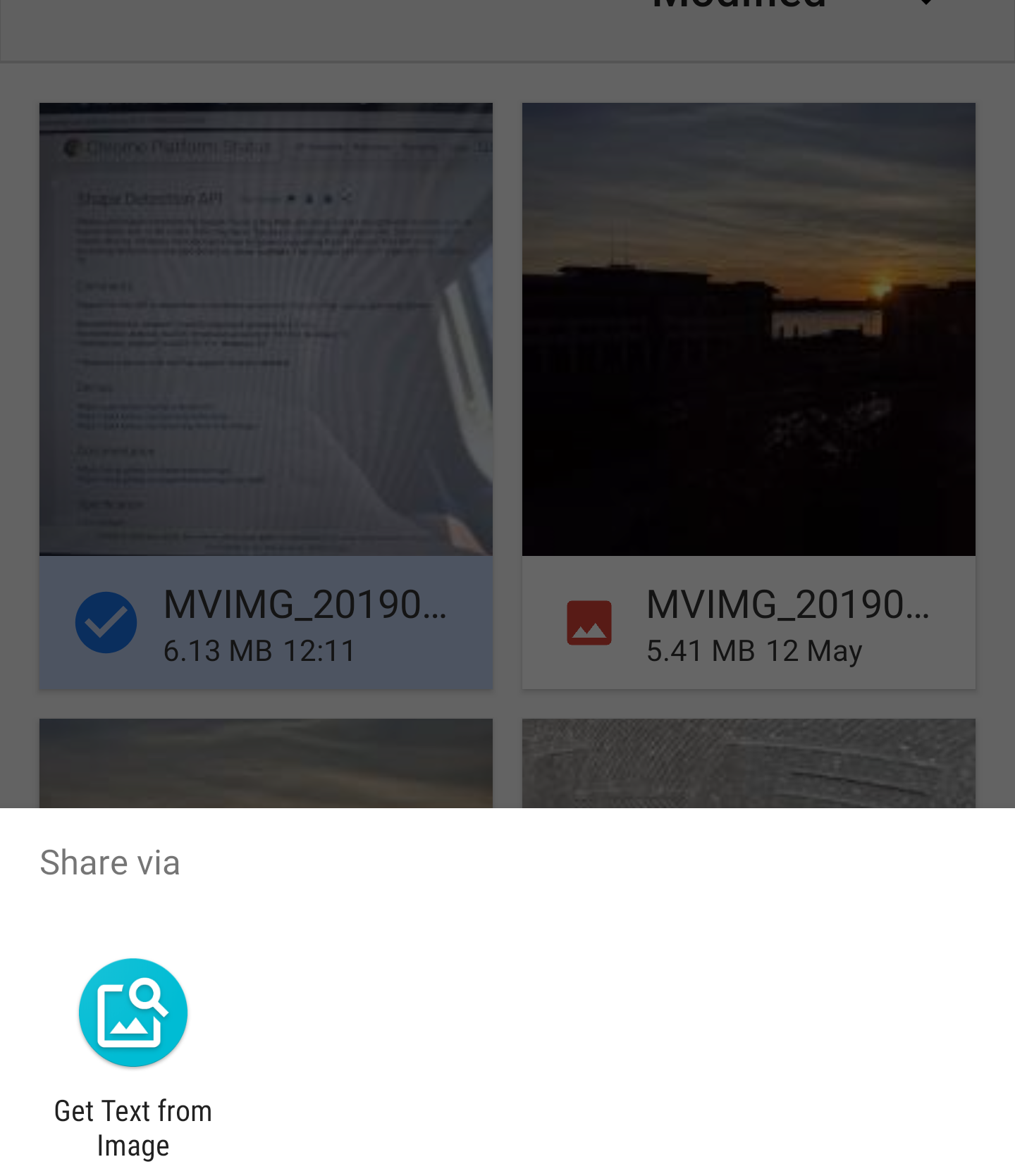
The Share Target API treats sharing files like a form post. When the file is shared to the Web App the service worker is activated the fetch handler is invoked with the file data. The data is now inside the Service Worker but I need it in the current window so that I can process it, the service knows which window invoked the request, so you can easily target the client and send it the data.
self.addEventListener('fetch', event => {
if (event.request.method === 'POST') {
event.respondWith(Response.redirect('/index.html'));
event.waitUntil(async function () {
const data = await event.request.formData();
const client = await self.clients.get(event.resultingClientId || event.clientId);
const file = data.get('file');
client.postMessage({ file, action: 'load-image' });
}());
return;
}
...
...
}
Once the image is in the user interface, I then process it with the text detection API.
navigator.serviceWorker.onmessage = (event) => {
const file = event.data.file;
const imgEl = document.getElementById('img');
const outputEl = document.getElementById('output');
const objUrl = URL.createObjectURL(file);
imgEl.src = objUrl;
imgEl.onload = () => {
const texts = await textDetector.detect(imgEl);
texts.forEach(text => {
const textEl = document.createElement('p');
textEl.textContent = text.rawValue;
outputEl.appendChild(textEl);
});
};
...
};
The biggest issue is that the browser doesn't naturally rotate the image (as you can see below), and the Shape Detection API needs the text to be in the correct reading orientation.
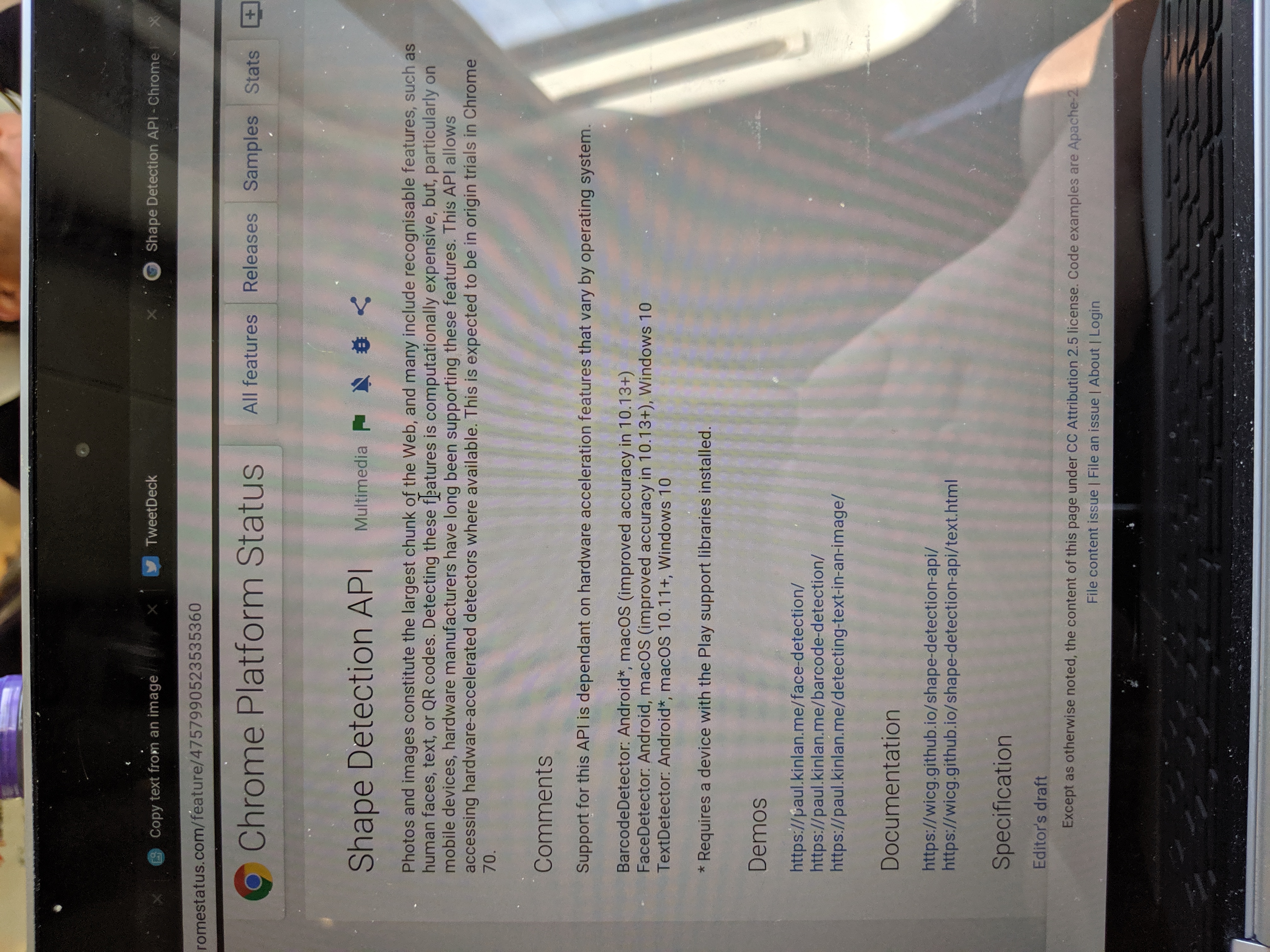
I used the rather easy to use EXIF-Js library to detect the rotation and then do some basic canvas manipulation to re-orientate the image.
EXIF.getData(imgEl, async function() {
// http://sylvana.net/jpegcrop/exif_orientation.html
const orientation = EXIF.getTag(this, 'Orientation');
const [width, height] = (orientation > 4)
? [ imgEl.naturalWidth, imgEl.naturalHeight ]
: [ imgEl.naturalHeight, imgEl.naturalWidth ];
canvas.width = width;
canvas.height = height;
const context = canvas.getContext('2d');
// We have to get the correct orientation for the image
// See also https://stackoverflow.com/questions/20600800/js-client-side-exif-orientation-rotate-and-mirror-jpeg-images
switch(orientation) {
case 2: context.transform(-1, 0, 0, 1, width, 0); break;
case 3: context.transform(-1, 0, 0, -1, width, height); break;
case 4: context.transform(1, 0, 0, -1, 0, height); break;
case 5: context.transform(0, 1, 1, 0, 0, 0); break;
case 6: context.transform(0, 1, -1, 0, height, 0); break;
case 7: context.transform(0, -1, -1, 0, height, width); break;
case 8: context.transform(0, -1, 1, 0, 0, width); break;
}
context.drawImage(imgEl, 0, 0);
}
And Voila, if you share an image to the app it will rotate the image and then analyse it returning the output of the text that it has found.
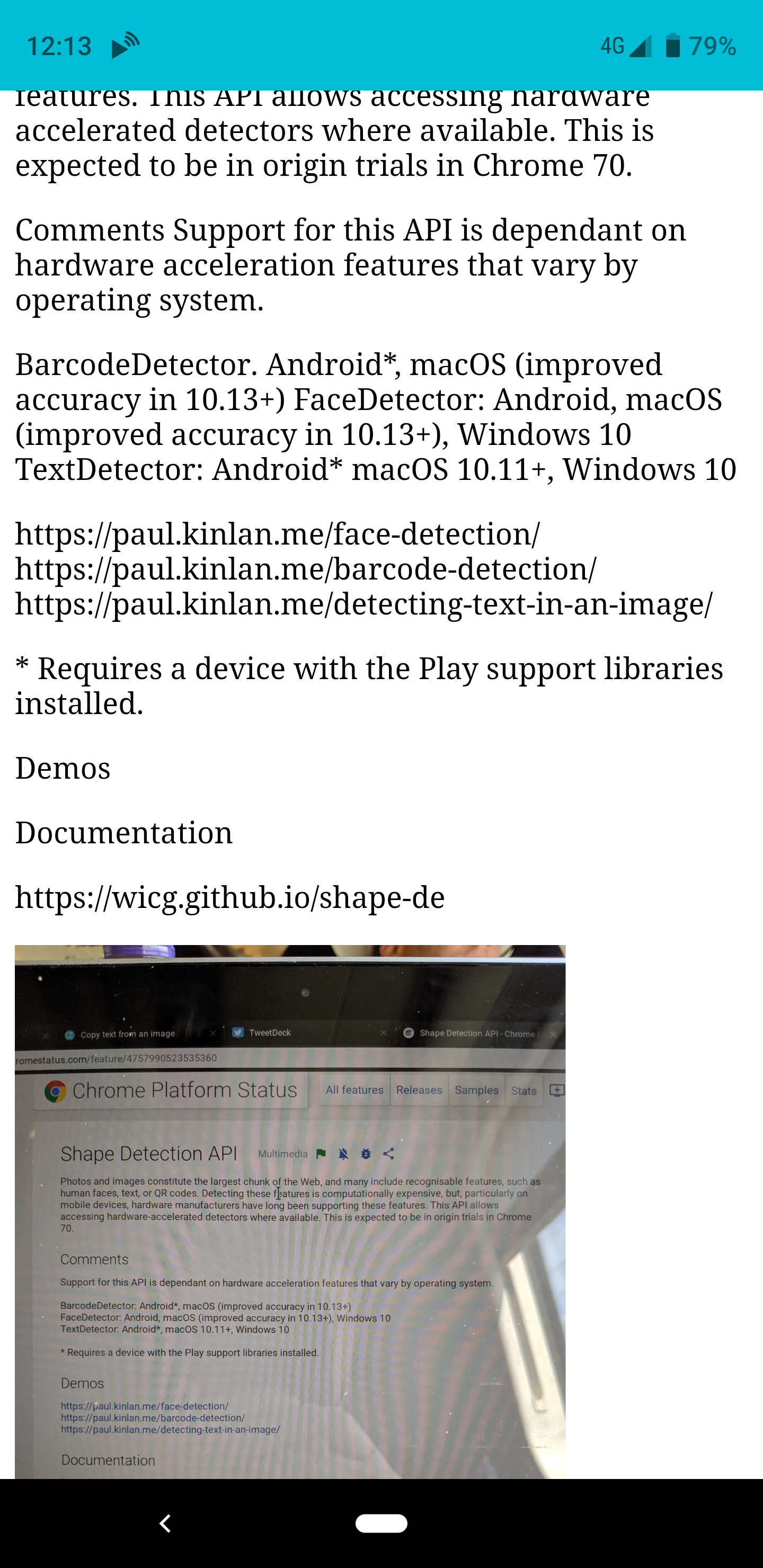
It was incredibly fun to create this little experiment, and it has been immediately useful for me. It does however, highlight the inconsistency of the web platform. These API's are not available in all browsers, they are not even available in all version of Chrome - this means that as I write this article Chrome OS, I can't use the app, but at the same time, when I can use it... OMG, so cool.